Всех приветствую, в данной статье рассмотрим следующий вопрос - возможно ли использование HIP на старых видеокартах с архитектурой GCN? Данную статью я планировал ещё во время обзора ноутбука HP 255 G9, но дошёл только сейчас.
Для справки - API HIP предназначено для исполнения CUDA кода на видеокартах AMD, с оптимизацией под карту (что вызывает некоторые проблемы). Был разработан во времена видеокарт на архитектуре GCN, позднее, начал поддерживать архитектуры cDNA и rDNA.
К сожалению, как таковых тестов в данной статье не будет, но зато будет рассматриваться возможен ли запуск HIP (про производительность поговорим позже). для данной статьи использовались встроенные графики в составе AMD Ryzen 5 5600G и AMD Ryzen 5 5625U.
Рассмотрим работу HIP под Windows.
Windows
Начнём с GPU-Z встройки.
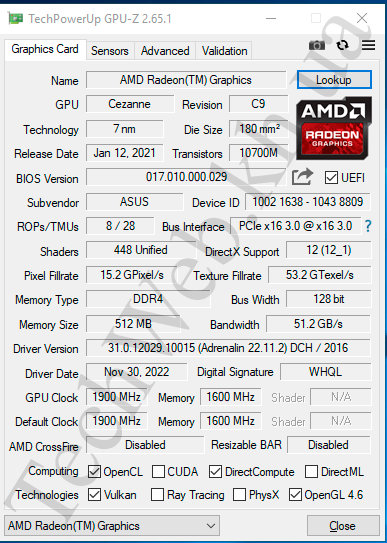
Тут приведён скриншот драйвера старой версии (в драйвере новой версии есть поддержка DirectML). Видим, что данная встройка имеет 448 шейдерных блока. Частота оперативной памяти составляет 3200 МГц.
Теперь рассмотрим, как сам HIP определяет устройство. На самой новой версии получаем следующую ошибку:
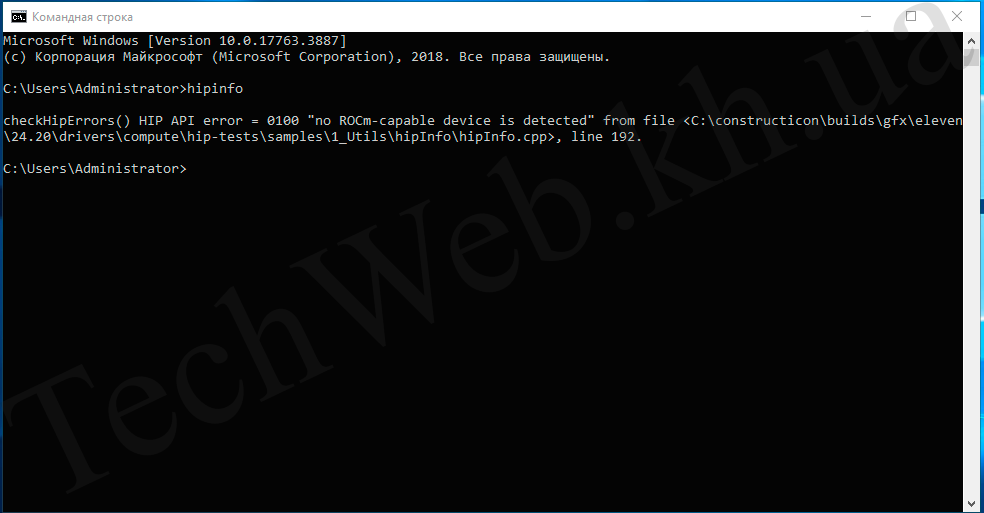 А на версии 5.7 получаем такую картину:
А на версии 5.7 получаем такую картину:
--------------------------------------------------------------------------------device# 0Name: AMD Radeon (TM) GraphicspciBusID: 4pciDeviceID: 0pciDomainID: 0multiProcessorCount: 7maxThreadsPerMultiProcessor: 2560isMultiGpuBoard: 0clockRate: 1800 MhzmemoryClockRate: 1333 MhzmemoryBusWidth: 0totalGlobalMem: 3.37 GBtotalConstMem: 2147483647sharedMemPerBlock: 64.00 KBcanMapHostMemory: 1regsPerBlock: 0warpSize: 64l2CacheSize: 4194304computeMode: 0maxThreadsPerBlock: 1024maxThreadsDim.x: 1024maxThreadsDim.y: 1024maxThreadsDim.z: 1024maxGridSize.x: 2147483647maxGridSize.y: 65536maxGridSize.z: 65536major: 9minor: 0concurrentKernels: 1cooperativeLaunch: 0cooperativeMultiDeviceLaunch: 0isIntegrated: 0maxTexture1D: 16384maxTexture2D.width: 16384maxTexture2D.height: 16384maxTexture3D.width: 2048maxTexture3D.height: 2048maxTexture3D.depth: 2048isLargeBar: 0asicRevision: 0maxSharedMemoryPerMultiProcessor: 64.00 KBclockInstructionRate: 1000.00 Mhzarch.hasGlobalInt32Atomics: 1arch.hasGlobalFloatAtomicExch: 1arch.hasSharedInt32Atomics: 1arch.hasSharedFloatAtomicExch: 1arch.hasFloatAtomicAdd: 1arch.hasGlobalInt64Atomics: 1arch.hasSharedInt64Atomics: 1arch.hasDoubles: 1arch.hasWarpVote: 1arch.hasWarpBallot: 1arch.hasWarpShuffle: 1arch.hasFunnelShift: 0arch.hasThreadFenceSystem: 1arch.hasSyncThreadsExt: 0arch.hasSurfaceFuncs: 0arch.has3dGrid: 1arch.hasDynamicParallelism: 0gcnArchName: gfx90c:xnack-peers:non-peers: device#0
memInfo.total: 3.37 GBmemInfo.free: 3.23 GB (96%)
Из увиденного делаем вывод о том, что под Windows, максимальная версия, которая нормально поддерживает GCN устройства - 5.7.
Для проверки работы и поведения программ с HIP, что под Windows, что под Linux, для наглядности, будем использовать llama.cpp и blender. Начнём с blender.
На самой новой версии картина вот такая:
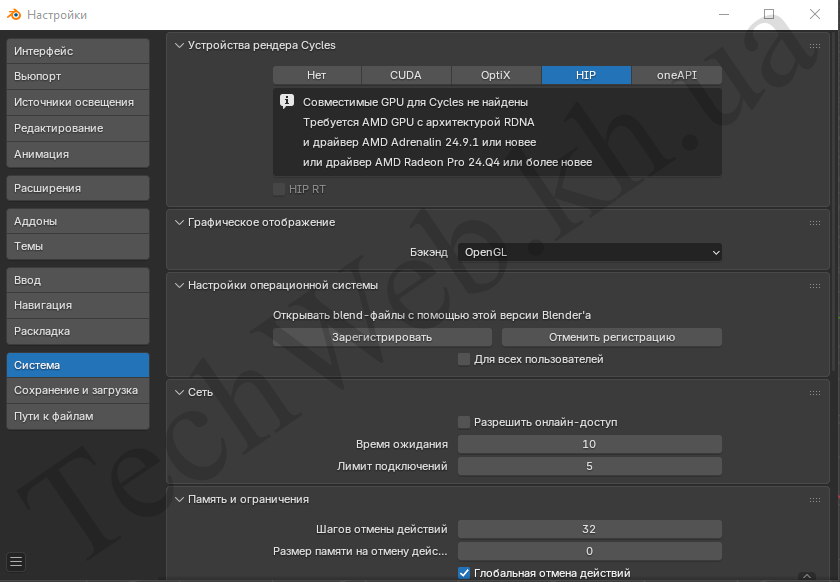 Видим, что не поддерживается и требует хотя бы видеокарт с архитектурой rDNA.
Видим, что не поддерживается и требует хотя бы видеокарт с архитектурой rDNA.
Возьмём более старую версию - 4.2:
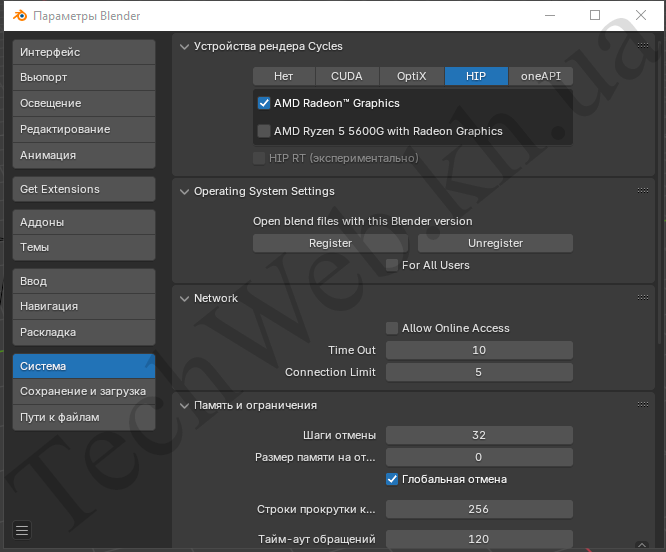
Тут уже спокойно определяется. Надо отметить, что для других карт на архитектуре GCN, последняя поддерживаемая версия может быть другой - это надо учитывать.
llama.cpp так завести и не удалось, потому что для его работы нужен HIP 6.1 как минимум. А старые видеокарты с GCN просто не поддерживаются в HIP 6.1. Отмечу, что на Linux аналогичная картина. Собственно к нему и переходим.
Linux
Использовалась Ubuntu 24.04.4. Начнём с вывода rocminfo последней версии:
rocminfoROCk module version 6.16.6 is loaded=====================HSA System Attributes=====================Runtime Version: 1.18Runtime Ext Version: 1.14System Timestamp Freq.: 1000.000000MHzSig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)Machine Model: LARGESystem Endianness: LITTLEMwaitx: DISABLEDXNACK enabled: YESDMAbuf Support: YESVMM Support: YES
==========HSA Agents==========*******Agent 1******* Name: AMD Ryzen 5 5625U with Radeon Graphics Uuid: CPU-XX Marketing Name: AMD Ryzen 5 5625U with Radeon Graphics Vendor Name: CPU Feature: None specified Profile: FULL_PROFILE Float Round Mode: NEAR Max Queue Number: 0(0x0) Queue Min Size: 0(0x0) Queue Max Size: 0(0x0) Queue Type: MULTI Node: 0 Device Type: CPU Cache Info: L1: 32768(0x8000) KB Chip ID: 0(0x0) ASIC Revision: 0(0x0) Cacheline Size: 64(0x40) Max Clock Freq. (MHz): 4390 BDFID: 0 Internal Node ID: 0 Compute Unit: 12 SIMDs per CU: 0 Shader Engines: 0 Shader Arrs. per Eng.: 0 WatchPts on Addr. Ranges:1 Memory Properties: Features: None Pool Info: Pool 1 Segment: GLOBAL; FLAGS: FINE GRAINED Size: 6899444(0x6946f4) KB Allocatable: TRUE Alloc Granule: 4KB Alloc Recommended Granule:4KB Alloc Alignment: 4KB Accessible by all: TRUE Pool 2 Segment: GLOBAL; FLAGS: EXTENDED FINE GRAINED Size: 6899444(0x6946f4) KB Allocatable: TRUE Alloc Granule: 4KB Alloc Recommended Granule:4KB Alloc Alignment: 4KB Accessible by all: TRUE Pool 3 Segment: GLOBAL; FLAGS: KERNARG, FINE GRAINED Size: 6899444(0x6946f4) KB Allocatable: TRUE Alloc Granule: 4KB Alloc Recommended Granule:4KB Alloc Alignment: 4KB Accessible by all: TRUE Pool 4 Segment: GLOBAL; FLAGS: COARSE GRAINED Size: 6899444(0x6946f4) KB Allocatable: TRUE Alloc Granule: 4KB Alloc Recommended Granule:4KB Alloc Alignment: 4KB Accessible by all: TRUE ISA Info:*******Agent 2******* Name: gfx90c Uuid: GPU-XX Marketing Name: AMD Radeon Graphics Vendor Name: AMD Feature: KERNEL_DISPATCH Profile: BASE_PROFILE Float Round Mode: NEAR Max Queue Number: 128(0x80) Queue Min Size: 64(0x40) Queue Max Size: 131072(0x20000) Queue Type: MULTI Node: 1 Device Type: GPU Cache Info: L1: 16(0x10) KB L2: 1024(0x400) KB Chip ID: 5607(0x15e7) ASIC Revision: 0(0x0) Cacheline Size: 64(0x40) Max Clock Freq. (MHz): 1800 BDFID: 1024 Internal Node ID: 1 Compute Unit: 7 SIMDs per CU: 4 Shader Engines: 1 Shader Arrs. per Eng.: 1 WatchPts on Addr. Ranges:4 Coherent Host Access: FALSE Memory Properties: APU Features: KERNEL_DISPATCH Fast F16 Operation: TRUE Wavefront Size: 64(0x40) Workgroup Max Size: 1024(0x400) Workgroup Max Size per Dimension: x 1024(0x400) y 1024(0x400) z 1024(0x400) Max Waves Per CU: 40(0x28) Max Work-item Per CU: 2560(0xa00) Grid Max Size: 4294967295(0xffffffff) Grid Max Size per Dimension: x 2147483647(0x7fffffff) y 65535(0xffff) z 65535(0xffff) Max fbarriers/Workgrp: 32 Packet Processor uCode:: 480 SDMA engine uCode:: 40 IOMMU Support:: None Pool Info: Pool 1 Segment: GLOBAL; FLAGS: COARSE GRAINED Size: 3449720(0x34a378) KB Allocatable: TRUE Alloc Granule: 4KB Alloc Recommended Granule:2048KB Alloc Alignment: 4KB Accessible by all: FALSE Pool 2 Segment: GLOBAL; FLAGS: EXTENDED FINE GRAINED Size: 3449720(0x34a378) KB Allocatable: TRUE Alloc Granule: 4KB Alloc Recommended Granule:2048KB Alloc Alignment: 4KB Accessible by all: FALSE Pool 3 Segment: GROUP Size: 64(0x40) KB Allocatable: FALSE Alloc Granule: 0KB Alloc Recommended Granule:0KB Alloc Alignment: 0KB Accessible by all: FALSE ISA Info: ISA 1 Name: amdgcn-amd-amdhsa--gfx90c:xnack+ Machine Models: HSA_MACHINE_MODEL_LARGE Profiles: HSA_PROFILE_BASE Default Rounding Mode: NEAR Default Rounding Mode: NEAR Fast f16: TRUE Workgroup Max Size: 1024(0x400) Workgroup Max Size per Dimension: x 1024(0x400) y 1024(0x400) z 1024(0x400) Grid Max Size: 4294967295(0xffffffff) Grid Max Size per Dimension: x 2147483647(0x7fffffff) y 65535(0xffff) z 65535(0xffff) FBarrier Max Size: 32 ISA 2 Name: amdgcn-amd-amdhsa--gfx9-generic:xnack+ Machine Models: HSA_MACHINE_MODEL_LARGE Profiles: HSA_PROFILE_BASE Default Rounding Mode: NEAR Default Rounding Mode: NEAR Fast f16: TRUE Workgroup Max Size: 1024(0x400) Workgroup Max Size per Dimension: x 1024(0x400) y 1024(0x400) z 1024(0x400) Grid Max Size: 4294967295(0xffffffff) Grid Max Size per Dimension: x 2147483647(0x7fffffff) y 65535(0xffff) z 65535(0xffff) FBarrier Max Size: 32*** Done ***
Как видим, несмотря на отсутствия официальной поддержки, rocminfo спокойно определяет GPU. Отмечу, что вместе с HIP ставиться OpenCL и Vulkan драйвер.
Если про llama.cpp было написано выше, насчёт blender ситуация неоднозначная. Начнём сразу с версии 4.2. 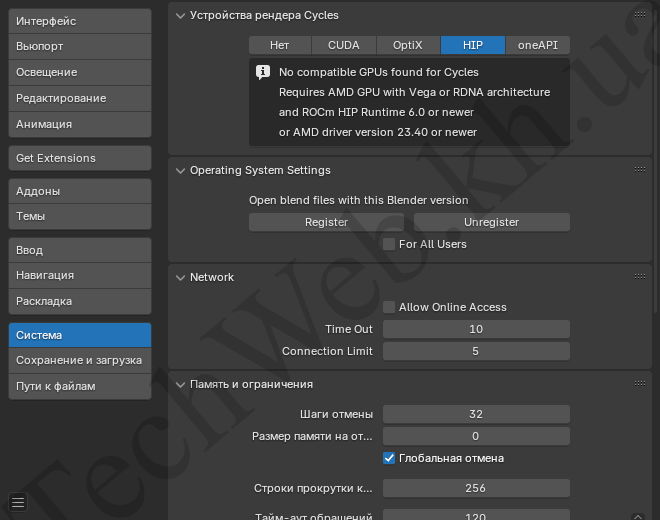 Как видим, несмотря на установленный HIP, blender не может найти доступное устройство. А вот с OpenCL другая ситуация:
Как видим, несмотря на установленный HIP, blender не может найти доступное устройство. А вот с OpenCL другая ситуация:
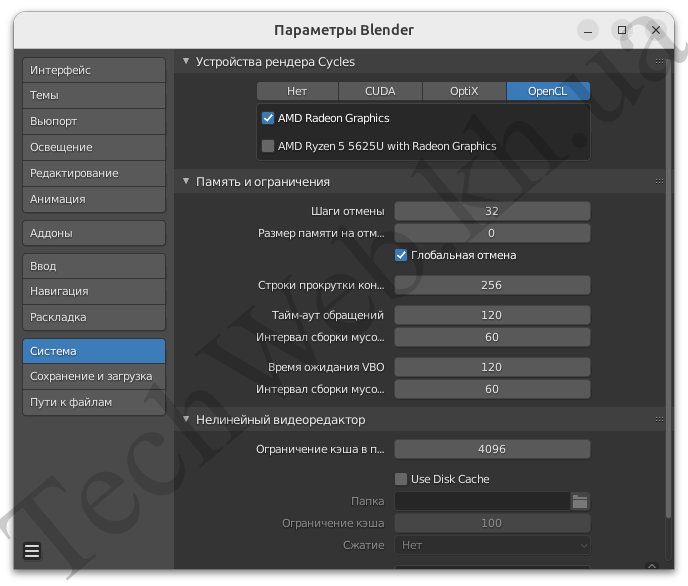 Как видим, OpenCL спокойно определился.
Как видим, OpenCL спокойно определился.
Выводы
Начнём с Windows. Видеокарты с архитектурой GCN нормально поддерживаются вплоть до версии 5.7 включительно (некоторые карты поддерживаются и в новых версиях - касается только топовых карт и серверных ускорителей Instinct). Производительность может быть низкой (потому что задача не переложилась на видеокарту) или более менее нормальной (если всё будет работать нормально). rDNA спокойно работает с HIP, так что, вместе с ними, HIP можно спокойно использовать. Для GCN альтернативами являются OpenCL и Vulkan, которые будут всегда с ними работать. На rDNA тоже можно их использовать, но только в том случаи, если на этих API производительность выше или только они и доступны.
С Linux другая ситуация. GCN карты определяются, но есть нюансы. Первое - для других карт, которые официально не поддерживались, нужны Tenselib, собранный специально под нужную карту. Второе - даже если имеется поддерживаемая видеокарта, не факт, что она заработает с HIP. Отмечу, что шанс работы с HIP под Linux для GCN видеокарт гораздо выше, чем под Windows.
По итогу, можно сказать, что нормально завести HIP на GCN просто так не получиться. Можно, но нет гарантий на успешный результат. Является ли это трагедией? Нет. Можно использовать Vulkan и OpenCL, которые применяются в большом количестве ПО. Например, на API OpenCL есть мод на генерацию мира в minecraft с помощью видеокарт на API OpenCL, Adobe Premier спокойно работает с OpenCL, старые версии Blender умеет с этим API работать, на Vulkan можно запустить тот же llama.cpp. Видно, что никакой трагедии в виде отсутствия HIP на видеокартах нет. И если прям надо CUDA код исполнить, то это можно выполнить силами ЦПУ, что быстрее до 2 раз, по сравнению с AVX2 (но работает не всегда).
А если говорить про rDNA, то тут всё просто - HIP тут работает всегда и без каких либо вопросов.
На этом всё, до встречи в следующих статьях.

