Всех приветствую, в данной статье рассмотрим работу чипа Rockchip RK3588, который имеет в своём составе NPU, с LLM, софтом для его работы и работу самих моделей, используя различные вычислительные блоки, такие как процессор, который состоит из 4 ядер Cortex-A76 и 4 Cortex-A55, и встроенная графика Mali G610 с 4 вычислительными блоками и собственно NPU. Про саму производительность чипа описано в статье годовалой давности и середины лета.
Софт
Для начала определим софт, который будет использоваться и библиотек для работы выбранного софта.
Начнём с NPU. Будет использоваться драйвер RKNPU. Почему? А всё просто – он поддерживает больше API для работы с нейросетями, чем открытый драйвер Rocket. Соответственно, вместе с этим, используется наборы инструментов разработчиков rknn-llm, rknn-toolkit-2, rknn-toolkite-lite2.
Про инференс поговорим чуть попозже, но обучение на NPU пока никто не делал (и ПО для него это не подразумевает).
Так как нужно сравнить производительность на различных блоках, которые могут обрабатывать языковые модели, будут использоваться следующие программы:
Рассмотрим каждое ПО по отдельности и в конце сравним их между собой.
llama.cpp
Если говорить про llama.cpp, то понятно, на чём он будет запускаться – на CPU (без использования API Kleidi AI, так как, на ARMv8, как в данном случаи, производительность такая же или чуть хуже, а на ARMv9 результат улучшается) и на GPU с использованием API Vulkan (OpenCL хоть и доступен для iGPU, но llama.cpp его не поддерживает для данной встроенной графики). Vulkan работает кое как (могу сказать точно, что он работает на mesa от kisak, версии 25.2.8), но работает, но на Ubuntu mesa он уже не работает (с чем это связано – сложно сказать, предположу, что с параметрами компиляции mesa).
RKLLAMA
Данная программа является аналогом ollama, но только для RKNPU, предназначен для более простого запуска rkllm моделей (формат языковых моделей для работы на RKNPU). Поддержка мультимодальных моделей есть, но мне их завести не удалось. Также есть веб-интерфейс в виде отдельной программы.
rk-llama.cpp
Данная программа является уже аналогом llama.cpp для RKNPU. Отмечу, что в отличии RKLLAMA, данная программа уже умеет работать с gguf моделями, при этом, с мультимодальными моделями он работает чисто на процессоре.
Теперь начнём тестировать эти программы.
Тестирование
Сравним и потестируем всё это настолько, насколько это возможно. Во всех вариантах llama-bench в составе llama.cpp можно провести тестирование, но есть нюансы:
1) API Vulkan то работал, то нет, но в llama-bench постоянно не работал;
2) rk-llama.cpp переменчиво работает с моделями, которые имеют 8-битную квантизацию;
3) В RKLLAMA теста производительности нет.
По этой причине, решил немного переделать методику тестирования, которая изначально планировалась для статьи. Для начала, в том же llama-bench, протестируем rk-llama.cpp и llama.cpp. Для тестирования использовалась модель Qwen2.5 0.5B Instruct FP16.
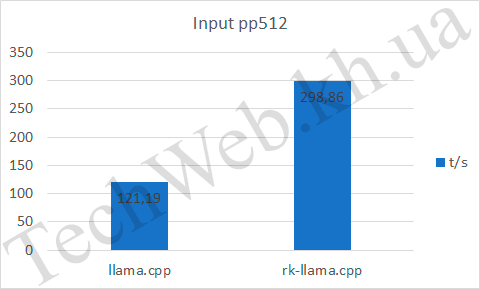
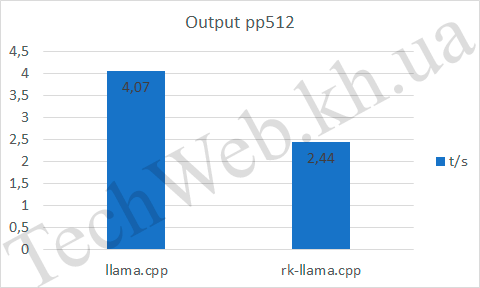
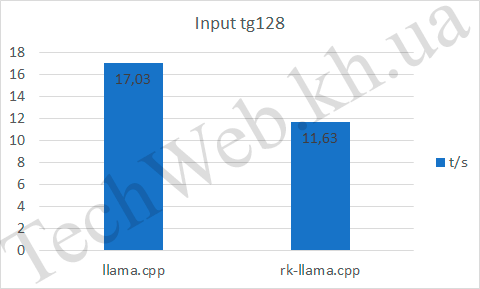
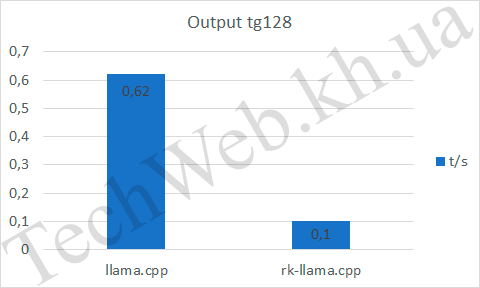
Если говорить про pp512, то видим, что RKNPU, на входе быстрее почти в 3 раза (и это, при неполной нагрузке NPU). А на выходе уступает уже процессору. Также он уступает в tg128 по всем параметрам.
Теперь проведём тест ответа на 1 вопрос. Вопрос был задан такой – “tell me about openai”. В сравнение добавим ещё API Vulkan. Использовалась та же модель - Qwen2.5 0.5B Instruct FP16.
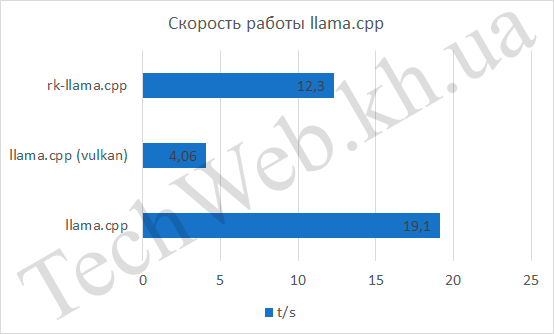
API Vulkan оказался аутсайдером, отстал лидера в 4,7 раза, на втором месте rk-llama.cpp, который отстал в 1,5 раза, а на первом месте оказался llama.cpp, который работал на CPU. С первым понятно – он работает кое как, со вторым не так всё просто, видимо сказывается низкая скорость в tg128. Ниже приведу и другие параметры, которые были получены при тестировании c этим же вопросом.
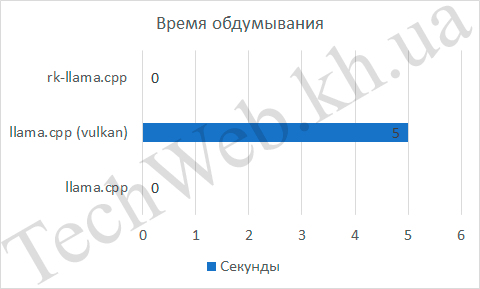
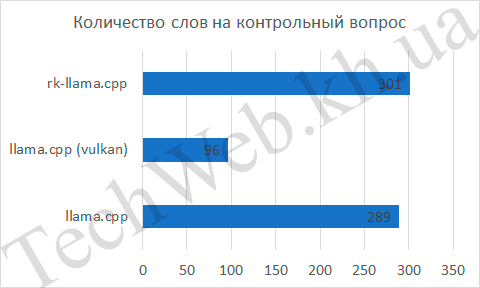
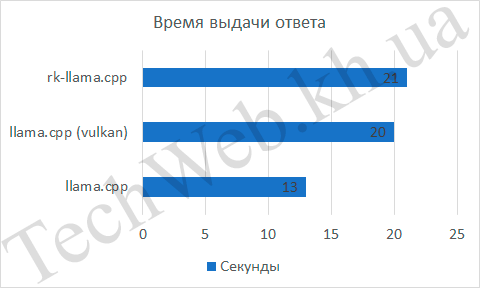
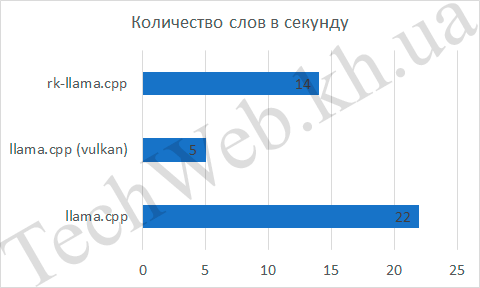
Проанализируем те параметры, которые можно вытащить из ответа нейросети, а это скорость обдумывания ответа, количество слов, скорость ответа и, исходя из 2-х предыдущих величин, количество слов в секунду. Для rk-llama и llama.cpp скорость обдумывания была равна 0, в то же время, встроенная графика была на 5 с медленнее. Если количество слов и время выдачи ответа не так интересны (они нужны просто как наглядные данные, чтобы было понятно, как высчитывалось следующее значение), так как следующий график более показательный – количество слов в секунду. По нему видно, что llama.cpp занял первое место с отрывом в 57%, по сравнению с rk-llama.cpp и в 4,4 раза, по сравнению с API Vulkan.
По этому тесту, можно сделать промежуточный вывод о том, что для gguf моделей лучше использовать процессорную часть RK3588, хоть и RKNPU показывает хорошую производительность, но скорость вывода так себе .
Теперь проведём сравнение RKLLAMA и llama.cpp. Прежде чём начнём тестирование, нужно добавить следующие моменты для понимания:
1) Hybrid ratio для модели в RKLLAMA был выбран 0,5. Разница между 0 и 1 я не заметил;
2) Этот тест нужен для того, чтобы понять, стоит ли пытаться конвертировать модели в rkllm;
3) Использовалась модель Qwen2.5 1.5B Q8 для llama.cpp, а для RKLLAMA – Qwen 2.5 1.5B w8a8.
Перейдём, собственно, к результатам теста.
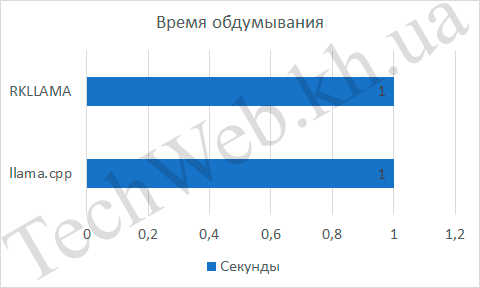
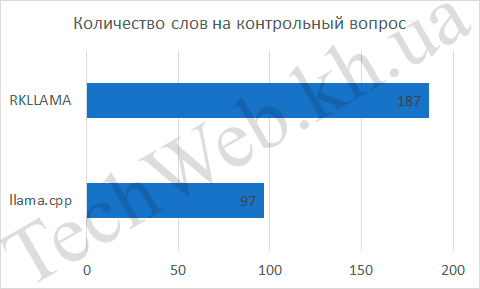
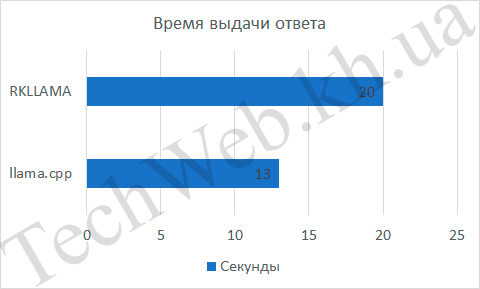
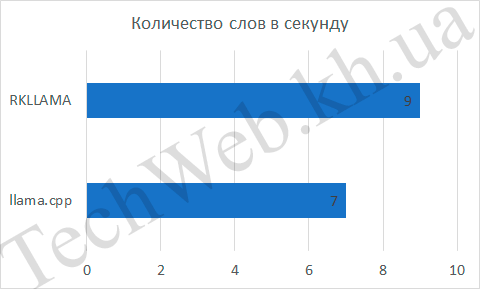
Если время обдумывания одинаковое, то количество слов в минуту было разное. Для llama.cpp это составило 7 слов/с, а для RKLLAMA – 9 слов/с. Разница составила итого 29% процентов. Хорошая разница, но хотелось бы большего.
Выводы
Исходя из тестов выше, сделаем выводы о том, на чём таки лучше запускать ИИ модели. Кратко о каждом вычислительном блоке/API.
Хоть RKNPU будет мощнее, по сравнению с процессорной частью чипа, но сталкивается с проблемами в софте, который был разработан, чтобы на нём было просто запускать языковые модели. Да, оно работает, если RKLLAMA довольно стабильна, но с проблемой, что нужно запускать модели в поприетарном формате, то rk-llama.cpp плохо работает с 8-битной квантизацией (а может и не только, но это надо ещё выявлять).
Если говорить про API Vulkan, то он работает на текущий момент кое как, но видно, что хоть и есть некоторые подвижки, работа не очень стабильна и с серьёзными багами.
По итогу, можно сказать, что RK3588 спокойно подходит для запуска языковых моделей (будь это маленькие fp16/fp32 модели или модели с квантизацией 4-8 бит).
В конце скажу немного слов про RK356x (хоть статья не о них, но я решил их упомянуть, чтобы было понятно, как они работают). rk-llama.cpp работает с ним, но выдаёт ошибки, так как под него нет файла конфигурации. Производительность неплохая – всего в 4,2 раза отстаёт от RK3588. И пока RKLLAMA официально не поддерживает данную линейку чипов.
По итогу, можно сказать, что лучше запускать модели на NPU и CPU. При этом пока запуск моделей на встроенной графике невозможно рекомендовать к использованию (по описанным выше причинам).
В следующий раз поговорим про другие модели для компьютерного зрения, генерацию картинок и распознавание текста и т.д., которые можно запустить на RK3588.

